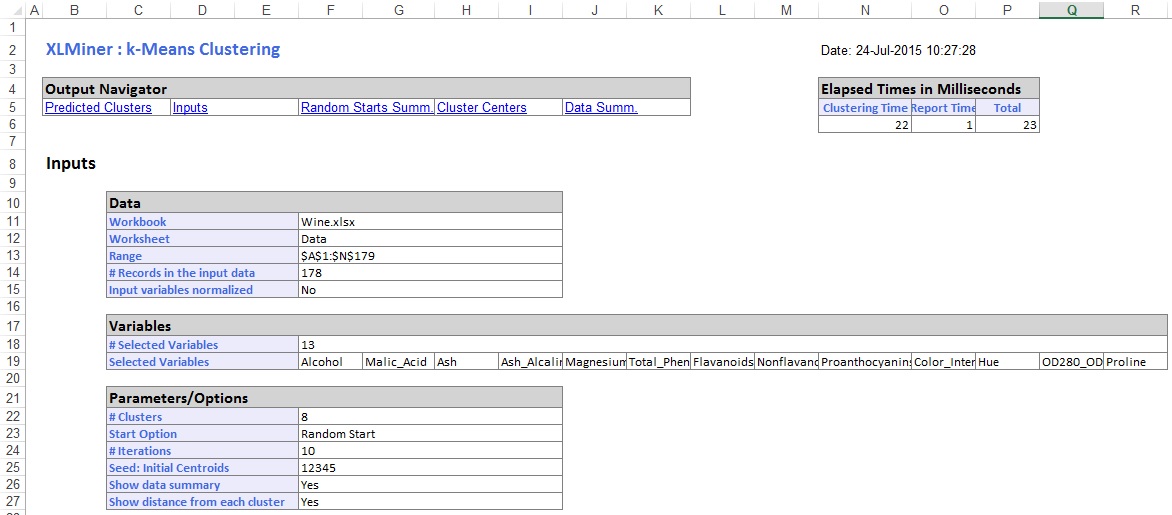
The results can be compared by examining the clusters or by a numeric measure such as the clusters’ distortion, enter 8. This is the parameter k in the k-means clustering algorithm. The number of clusters should be at least 1 and at most the number of observations -1 in the data range. The configuration of clusters (and data separation) may differ from one starting partition to another. At each iteration, the records are assigned to the cluster with the closest centroid, or center. After each iteration, the distance from each record to the center of the cluster is calculated. In the beginning we determine number of cluster K and we assume the centroid or center of these clusters. Note that there are four dimensions in the data and that only the first two dimensions are used to draw the plot below. Some black points close to the green centre (asterisk) are actually closer to the black centre in the four dimensional space. They are the examples of K-means being run on 90 data points (with k =3). The data does not have well defined clusters as in the previous examples. Figure 3 shows the initial data points before clustering and figure 4 shows the result after 16 iterations. At # Clusters, and increased if the clusters are too broad. Since, K-means is used for exploratory data mining, you must examine the clustering results anyways to determine which clusters make sense. The value for k can be decreased if some clusters are too small, which is the sum of the squared differences between each data point and its corresponding centroid.